
流失率指在一段时间内流失掉的用户比例。时间单位可以是周、月或季度等,但所有指标的时间单位应保持一致,这样才具有可比性。在免费增值模式或免费试用模式中,你同时服务着(不付费)用户和(付费)客户,因此二者的流失率也应该分开考量。流失率这一指标虽然看上去简单,但如果样本或时间选得不好,就有可能产生误导,尤其是对于增长率经常变化的公司而言。
免费用户流失和付费用户流失的定义不同。免费用户“流失”指用户注销账号或再也没回来使用过;而付费用户“流失”则指他们注销了账号并停止支付费用,或是降级到免费版。我们建议将90天(或更短时间)内没有登录过的用户视为非活跃用户。从第90天起,我们就可以认定已经流失了这些用户;在这个永远在线的世界上,90天就像是一万年那么长。
但请记住,你仍有机会将流失的用户邀请回来。一是当你的功能得到显著升级时,Path10 就曾在应用改版后成功召回了一部分用户;二是当你拥有可以每日发给用户的内容时,Memolane11 在向用户发送往年回忆时也做到了这一点。
10 一个私密社交网络,由Facebook前高级主管大卫·莫林创建。——译者注
11 一款总结你在各种社交网络“历史上的今天”的应用。——译者注
Shopify12 的数据科学家史蒂夫·诺布尔13 在其博客14 中对流失率做了详尽的介绍,定义流失率的简单公式如下:
12 网店建站工具。——译者注
表9-1中这个简单的例子给出了一家SaaS公司在免费增值模式下的流失率计算。
表9-1:计算流失率的例子
| 1月 | 2月 | 3月 | 4月 | 5月 | 6月 | |
|---|---|---|---|---|---|---|
| 用户 | ||||||
| 起始人数 | 50 000 | 53 000 | 56 300 | 59 930 | 63 923 | 68 315 |
| 新增人数 | 3000 | 3600 | 4320 | 5184 | 6221 | 7465 |
| 总人数 | 53 000 | 56 600 | 60 920 | 66 104 | 72 325 | 79 790 |
| 活跃用户 | ||||||
| 起始人数 | 14 151 | 15 000 | 15 900 | 16 980 | 18 276 | 19 831 |
| 新增人数 | 849 | 900 | 1080 | 1296 | 1555 | 1866 |
| 总人数 | 15 000 | 15 900 | 16 980 | 18 276 | 19 831 | 21 697 |
| 付费用户 | ||||||
| 起始人数 | 1000 | 1035 | 1035 | 1049 | 1079 | 1128 |
| 新增人数 | 60 | 72 | 86 | 104 | 124 | 149 |
| 流失人数 | (25) | (26) | (27) | (29) | (30) | (33) |
| 总人数 | 1035 | 1081 | 1140 | 1216 | 1310 | 1426 |
表9-1记录了用户、活跃用户和付费用户三个指标。活跃用户指在注册后的一个月里有登录记录的用户。新用户的月增长速度为20%,其中30%的新用户在注册后的一个月内会使用这一服务,2%的新用户会转化为付费客户。
2月份的流失率计算如下所示:
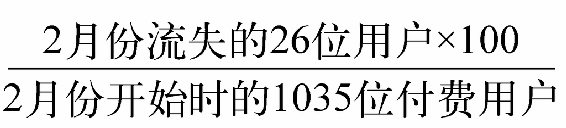
如果每个月的客户流失率为2.5%,就意味着每位客户的平均使用寿命为40个月(100/2.5)。这就是用于计算客户终身价值的依据(40个月×每位用户平均每月创造的营收)。
诺布尔解释道,由于特定时间内流失的用户数受到了整段时间的影响,而这段时间开始时的用户数只是一个瞬间变量而已,因此以这样简单的方式来计算流失率可能会引起混淆,特别是对于发展速度非常快或经常变化的创业公司而言。换言之,流失率并没有对用户的行为和数量做归一化处理,面对相同的用户行为,一不小心就会得出不同的流失率。
为修正这一缺陷,需使用另一种更复杂且更精确的方法来计算流失率,对这一时间段内的用户数取平均值,而不是只看时间段开始时的数据:

该公式把时间段开始和结束时的用户数取了平均值,这要比前一个公式好一些,但当用户数量迅速增长时,仍然存在一些问题。假设月初用户数为100,月末该数值增至10 000,则该公式假设月中的用户数为5050。但如果用户数正呈指数式增长的话,则这种算法并不正确。大部分用户都是在接近月末时注册的,而大部分流失也是在此时段发生的,因此平均数并不具有代表性。
更糟糕的是,如果以“30天内未登录”为标准计算流失用户数,就相当于把上个月流失掉的用户数与这个月新增的用户数作比较,这比上一个问题还要严重,因为你观察的是一个后见性指标(上个月的损失)。因此当你发现任何不妥时,问题已经存在一个月了。
如果继续修正下去,计算会变得非常复杂。但有两种方法可以简化它。第一种是以断代 来衡量流失率,即以注册时间为基础比较新增用户和已流失用户的多少。第二种方法更为简单,即以天为单位计算流失率,这也是我们喜欢这种方法的原因。所选时间段越短,数据中的噪音也就越小。